Linux标准IO库
标准IO库
简介
所谓标准 I/O 库则是标准 C 库中用于文件 I/O 操作(譬如读文件、写文件等)相关的一系列库函数的集合,通常标准 I/O 库函数相关的函数定义都在头文件中。
设计库函数是为了提供比底层系统调用更为方便、好用的调用接口,虽然标准 I/O 构建于文件 I/O 之上,但标准 I/O 却有它自己的优势。
标准 I/O 和文件 I/O 的区别如下:
⚫ 虽然标准 I/O 和文件 I/O 都是 C 语言函数,但是标准 I/O 是标准 C 库函数,而文件 I/O 则是 Linux
系统调用;
⚫ 标准 I/O 是由文件 I/O 封装而来,标准 I/O 内部实际上是调用文件 I/O 来完成实际操作的;
⚫ 可移植性:标准 I/O 相比于文件 I/O 具有更好的可移植性。
⚫ 性能、效率:标准 I/O 库在用户空间维护了自己的 stdio 缓冲区,所以标准 I/O 是带有缓存的,而
文件 I/O 在用户空间是不带有缓存的,所以在性能、效率上,标准 I/O 要优于文件 I/O。
FILE 指针
而对于标准 I/O 库函数来说,它们的操作是围绕 FILE 指针进行的,当使用标准 I/O 库函数打开或创建一个
文件时,会返回一个指向 FILE 类型对象的指针(FILE *),使用该 FILE 指针与被打开或创建的文件相关
联,然后该 FILE 指针就用于后续的标准 I/O 操作(使用标准 I/O 库函数进行 I/O 操作),所以由此可知,
FILE 指针的作用相当于文件描述符,只不过 FILE 指针用于标准 I/O 库函数中、而文件描述符则用于文件
I/O 系统调用中。
FILE 是一个结构体数据类型,它包含了标准 I/O 库函数为管理文件所需要的所有信息,包括用于实际
I/O 的文件描述符、指向文件缓冲区的指针、缓冲区的长度、当前缓冲区中的字节数以及出错标志等。FILE
数据结构定义在标准 I/O 库函数头文件 stdio.h 中。
标准输入、标准输出和标准错误
所谓标准输入设备指的就是计算机系统的标准的输入设备,通常指的是计算机所连接的键盘;而标准输出设备指的是计算机系统中用于输出标准信息的设备,通常指的是计算机所连接的显示器;标准错误设备则指的是计算机系统中用于显示错误信息的设备,通常也指的是显示器设备。
用户通过标准输入设备与系统进行交互,进程将从标准输入(stdin)文件中得到输入数据,将正常输出
数据(譬如程序中 printf 打印输出的字符串)输出到标准输出(stdout)文件,而将错误信息(譬如函数调用报错打印的信息)输出到标准错误(stderr)文件。
打开文件fopen()
在标准 I/O 中,我们将使用库函数fopen()打开或创建文件.函数原型。
1 |
|
函数参数和返回值含义如下:
path:参数 path 指向文件路径,可以是绝对路径、也可以是相对路径。
mode:参数 mode 指定了对该文件的读写权限,是一个字符串。
返回值:调用成功返回一个指向 FILE 类型对象的指针(FILE *),该指针与打开或创建的文件相关联,
后续的标准 I/O 操作将围绕 FILE 指针进行。如果失败则返回 NULL,并设置 errno 以指示错误原因。
| mode | 说明 |
|---|---|
| r | 以只读方式打开文件 |
| r+ | 以可读、可写方式打开文件 |
| w | 以只写方式打开文件,如果参数path指定的文件存在,将文件长度截断为0,不存在则创建该文件 |
| w+ | 以可读、可写方式打开文件,如果参数 path 指定的文件存在,将文件长度截断为 0;如果指定文件不存在则创建该文件。 |
| a | 以只写方式打开文件,打开以进行追加内容(在文件末尾写入),如果文件不存在则创建该文件。 |
| a+ | 以可读、可写方式打开文件,以追加方式写入(在文件末尾写入),如果文件不存在则创建该文件。 |
虽然调用 fopen()函数新建文件时无法手动指定文件的权限,但却有一个默认值:
1 | S_IRUSR | S_IWUSR | S_IRGRP | S_IWGRP | S_IROTH | S_IWOTH (0666) |
fclose()关闭文件
函数原型
1 |
|
参数 stream 为 FILE 类型指针,调用成功返回 0;失败将返回 EOF(也就是-1),并且会设置 errno 来
指示错误原因。
读文件和写文件
函数原型
1 |
|
库函数 fread()用于读取文件数据,其参数和返回值含义如下:
ptr:fread()将读取到的数据存放在参数 ptr 指向的缓冲区中;
size:fread()从文件读取 nmemb 个数据项,每一个数据项的大小为 size 个字节,所以总共读取的数据大
小为 nmemb * size 个字节。
nmemb:参数 nmemb 指定了读取数据项的个数。
stream:FILE 指针。
返回值:调用成功时返回读取到的数据项的数目(数据项数目并不等于实际读取的字节数,除非参数
size 等于 1);如果发生错误或到达文件末尾,则 fread()返回的值将小于参数 nmemb,那么到底发生了错误还是到达了文件末尾,fread()不能区分文件结尾和错误,究竟是哪一种情况,此时可以使用 ferror()或 feof()函数来判断。
库函数 fwrite()用于将数据写入到文件中,其参数和返回值含义如下:
ptr:将参数 ptr 指向的缓冲区中的数据写入到文件中。
size:参数 size 指定了每个数据项的字节大小,与 fread()函数的 size 参数意义相同。
nmemb:参数 nmemb 指定了写入的数据项个数,与 fread()函数的 nmemb 参数意义相同。
stream:FILE 指针。
返回值:调用成功时返回写入的数据项的数目(数据项数目并不等于实际写入的字节数,除非参数 size
等于 1);如果发生错误,则 fwrite()返回的值将小于参数 nmemb(或者等于 0)。
由此可知,库函数 fread()、fwrite()中指定读取或写入数据大小的方式与系统调用 read()、write()不同,
前者通过 nmemb(数据项个数)*size(每个数据项的大小)的方式来指定数据大小,而后者则直接通过一个 size 参数指定数据大小。
eg:
1 |
|
1 |
|
fseek定位
1 |
|
stream:FILE 指针。
offset:与 lseek()函数的 offset 参数意义相同。
whence:与 lseek()函数的 whence 参数意义相同。
返回值:成功返回 0;发生错误将返回-1,并且会设置 errno 以指示错误原因;与 lseek()函数的返回值
意义不同,这里要注意!
调用库函数 fread()、fwrite()读写文件时,文件的读写位置偏移量会自动递增,使用 fseek()可手动设置
文件当前的读写位置偏移量。
将一个文件的打开写入文件数据,并进行读取要使用fseek来将读写位置移动到头部才能读取,否则fead
读取后面的空白信息,没有内容。
ftell()函数
用于获取文件当前的读写位置偏移量,函数原型:
1 |
|
参数 stream 指向对应的文件,函数调用成功将返回当前读写位置偏移量;调用失败将返回-1,并会设置
errno 以指示错误原因。
feof函数
库函数 feof()用于测试参数 stream 所指文件的 end-of-file 标志,如果 end-of-file 标志被设置了,则调用
feof()函数将返回一个非零值,如果 end-of-file 标志没有被设置,则返回 0
1 |
|
ferror()函数
库函数 ferror()用于测试参数 stream 所指文件的错误标志,如果错误标志被设置了,则调用 ferror()函数
将返回一个非零值,如果错误标志没有被设置,则返回 0。
1 |
|
clearerr函数
库函数 clearerr()用于清除 end-of-file 标志和错误标志,当调用 feof()或 ferror()校验这些标志后,通常需
要清除这些标志,避免下次校验时使用到的是上一次设置的值,此时可以手动调用 clearerr()函数清除标志。
1 |
|
IO缓冲
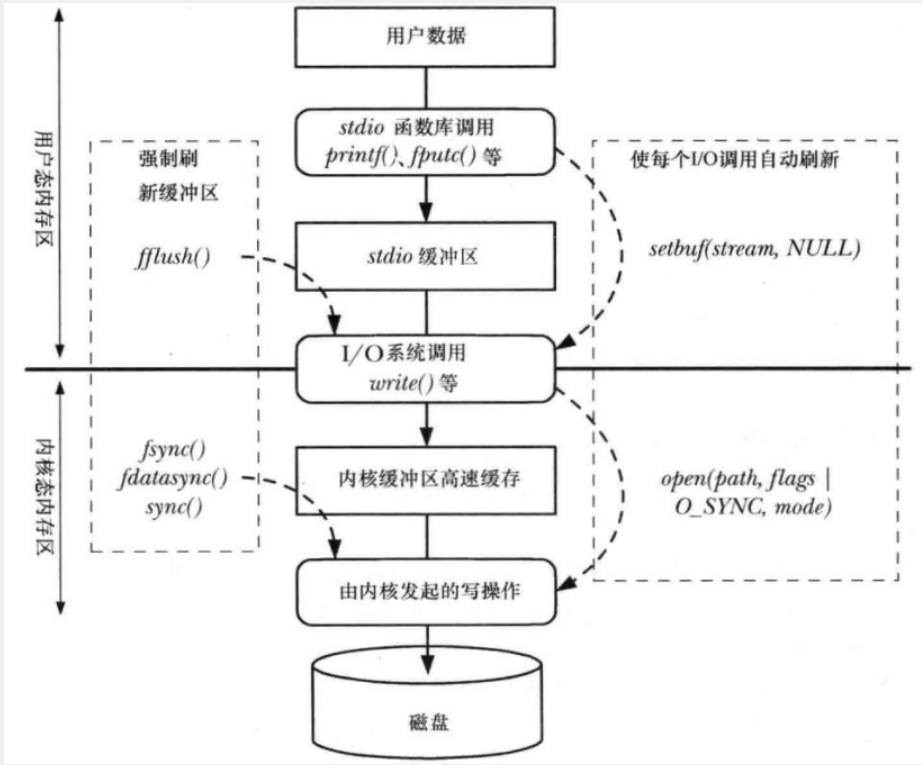
调用 write()后仅仅只是将这 5 个字节数据拷贝到了内核空间的缓冲区中,拷贝完成之后函数就返回了,在后面的某个时刻,内核会将其缓冲区中的数据写入(刷新)到磁盘设备中,所以由此可知,系统调用 write()与磁盘操作并不是同步的,write()函数并不会等待数据真正写入到磁盘之后再返回。如果在此期间,其它进程调用 read()函数读取该文件的这几个字节数据,那么内核将自动从缓冲区中读取这几个字节数据返回给应用程序。
这个内核缓冲区就称为文件 I/O 的内核缓冲。这样的设计,目的是为了提高文件 I/O 的速度和效率,使得系统调用 read()、write()的操作更为快速,不需要等待磁盘操作(将数据写入到磁盘或从磁盘读取出数据),磁盘操作通常是比较缓慢的。同时这一设计也更为高效,减少了内核操作磁盘的次数,譬如线程1 调用 write()向文件写入数据”abcd”,线程 2 也调用 write()向文件写入数据”1234”,这样的话,数据”abcd”和”1234”都被缓存在了内核的缓冲区中,在稍后内核会将它们一起写入到磁盘中,只发起一次磁盘操作请求;加入没有内核缓冲区,那么每一次调用 write(),内核就会执行一次磁盘操作。
刷新文件 I/O 的内核缓冲区
当我们在 Ubuntu 系统下拷贝文件到 U 盘时,文件拷贝完成之后,通常在拔掉 U 盘之前,需要执行 sync 命令进行同步操作,这个同步操作其实就是将文件 I/O 内核缓冲区中的数据更新到 U 盘硬件设备,所以如果在没有执行 sync 命令时拔掉 U 盘,很可能就会导致拷贝到 U 盘中的文件遭到破坏!
fsync()函数
系统调用 fsync()将参数 fd 所指文件的内容数据和元数据写入磁盘,只有在对磁盘设备的写入操作完成之后,fsync()函数才会返回。
1 |
|
参数 fd 表示文件描述符,函数调用成功将返回 0,失败返回-1 并设置 errno 以指示错误原因。
eg:
1 |
|
fdatasync()函数
系统调用 fdatasync()与 fsync()类似,不同之处在于 fdatasync()仅将参数 fd 所指文件的内容数据写入磁
盘。
1 |
|
sync()函数
系统调用 sync()会将所有文件 I/O 内核缓冲区中的文件内容数据和元数据全部更新到磁盘设备中。
1 |
|
O_DSYNC 标志
在调用 open()函数时,指定 O_DSYNC 标志,其效果类似于在每个 write()调用之后调用 fdatasync()函数
进行数据同步。
O_SYNC 标志
在调用 open()函数时,指定 O_SYNC 标志,使得每个 write()调用都会自动将文件内容数据和元数据刷
新到磁盘设备中,其效果类似于在每个 write()调用之后调用 fsync()函数进行数据同步
直接IO
Linux 允许应用程序在执行文件 I/O 操作时绕过内核缓冲区,从用户空间直接将数据传递到文件或磁盘设备,把这种操作也称为直接 I/O(direct I/O)或裸 I/O(raw I/O)。
因为直接 I/O 涉及到对磁盘设备的直接访问,所以在执行直接 I/O 时,必须要遵守以下三个对齐限制要求:
⚫ 应用程序中用于存放数据的缓冲区,其内存起始地址必须以块大小的整数倍进行对齐;
⚫ 写文件时,文件的位置偏移量必须是块大小的整数倍;
⚫ 写入到文件的数据大小必须是块大小的整数倍。
stdio缓冲
标准 I/O(fopen、fread、fwrite、fclose、fseek 等)是 C 语言标准库函数,而文件 I/O(open、read、write、close、lseek 等)是系统调用,虽然标准 I/O 是在文件 I/O 基础上进行封装而实现(譬如 fopen 内部实际上调用了 open、fread 内部调用了 read 等),但在效率、性能上标准 I/O 要优于文件 I/O,其原因在于标准 I/O 实现维护了自己的缓冲区,把这个缓冲区称为 stdio 缓冲区。为了减少调用系统调用的次数,标准 I/O 函数会将用户写入或读取文件的数据缓存在 stdio 缓冲区,然后再一次性将 stdio 缓冲区中缓存的数据通过调用系统调用I/O(文件 I/O)写入到文件 I/O 内核缓冲区或者拷贝到应用程序的 buf 中。
stdio缓冲区的函数
setvbuf()函数
1 |
|
stream:FILE 指针,用于指定对应的文件,每一个文件都可以设置它对应的 stdio 缓冲区。
buf:如果参数 buf 不为 NULL,那么 buf 指向 size 大小的内存区域将作为该文件的 stdio 缓冲区,因为stdio 库会使用 buf 指向的缓冲区,所以应该以动态(分配在堆内存)或静态的方式在堆中为该缓冲区分配一块空间,而不是分配在栈上的函数内的自动变量(局部变量)。如果 buf 等于 NULL,那么 stdio 库会自动分配一块空间作为该文件的 stdio 缓冲区(除非参数 mode 配置为非缓冲模式)。
mode:参数 mode 用于指定缓冲区的缓冲类型,可取值如下:
⚫ _IONBF:不对 I/O 进行缓冲(无缓冲)。意味着每个标准 I/O 函数将立即调用 write()或者 read(),并且忽略 buf 和 size 参数,可以分别指定两个参数为 NULL 和 0。标准错误 stderr 默认属于这一种类型,从而保证错误信息能够立即输出。
⚫ _IOLBF:采用行缓冲 I/O。在这种情况下,当在输入或输出中遇到换行符”\n”时,标准 I/O 才会执行文件 I/O 操作。对于输出流,在输出一个换行符前将数据缓存(除非缓冲区已经被填满),当输出换行符时,再将这一行数据通过文件 I/O write()函数刷入到内核缓冲区中;对于输入流,每次读取一行数据。对于终端设备默认采用的就是行缓冲模式,譬如标准输入和标准输出。
⚫ _IOFBF:采用全缓冲 I/O。在这种情况下,在填满 stdio 缓冲区后才进行文件 I/O 操作(read、write)。对于输出流,当 fwrite 写入文件的数据填满缓冲区时,才调用 write()将 stdio 缓冲区中的数据刷入内核缓冲区;对于输入流,每次读取 stdio 缓冲区大小个字节数据。默认普通磁盘上的常规文件默认常用这种缓冲模式。
size:指定缓冲区的大小。
返回值:成功返回 0,失败将返回一个非 0 值,并且会设置 errno 来指示错误原因。
setbuffer()函数
setbuffer函数类似setbuf()但是允许调用者指定buf缓冲区的大小
1 |
|
刷新 stdio 缓冲区
无论我们采取何种缓冲模式,在任何时候都可以使用库函数 fflush()来强制刷新(将输出到 stdio 缓冲区中的数据写入到内核缓冲区,通过 write()函数)stdio 缓冲区,该函数会刷新指定文件的 stdio 输出缓冲区。
1 |
|
1 |
|
在一些其它的情况下,也会自动刷新 stdio 缓冲区,譬如当文件关闭时、程序退出时。