
无题
title:RVV向量化
注意:
首先硬件可能支持不同版本的向量扩展,这之间不同版本互不兼容。
qemu上虽然可以跑RVV程序,但是开销比标量运算还大,所以只能做程序验证,实际运行效率要上实际的riscvgv的机器上才行。
ubuntu22.04尽管使用qemu但是也不支持rvv,因为kernel内核中的mstatus寄存器(机器模式下的状态寄存器)未初始化,当mstatus.vs域值被写0时候,试图执行向量指令或访问向量寄存器均会引发非法指令异常。
自动向量化和手动向量化
关于向量化:
- 对GCC或者LLVM进行开发(自动向量化)
**前端编译扩展 Target Transform Info (TTI)**:
- 定义目标架构的向量化能力(RVV 支持可扩展向量)。
- 例如为 RISC-V 增强
getRegisterBitWidth和getTypeLegalizationCost方法。 修改 Loop 和 SLP Vectorizer:
- 添加对 RVV 动态向量寄存器的支持。
- 修改默认的向量化策略以生成动态向量类型。
支持 RVV 的 IR 到目标代码映射:
- 在后端的
SelectionDAG或GlobalISel中实现 RVV 指令的生成逻辑。
- Intrinsic函数的开发(手动向量化)
- 本质上跳过了自动向量化的逻辑,不需要向量化Pass介入。
- 直接提供了向量化代码的“翻译规则”,编译器无需再生成向量化逻辑或 IR,代码中调用的 Intrinsic 已经指定了目标平台指令。
- 自动向量化与显式使用 Intrinsic 的关系
- 显式调用 Intrinsic:
- 开发者直接编写 Intrinsic,相当于手动向量化。
- 编译器只负责将这些 Intrinsic 映射到硬件指令,而不会尝试进行进一步优化。
- 优点:避免冗余优化,无需等待编译器的进一步支持。
- 缺点:增加了维护成本。
- 自动向量化:
- 开发者编写标量代码,向量化 Pass 根据硬件平台的能力和代码逻辑,自动生成调用 Intrinsic 的 IR。
- 编译器根据向量化 Pass 生成的规则,优化代码并映射到目标平台指令。
向量扩展
RISC-V 向量扩展(RVV)是一种灵活的矢量处理架构,允许程序在运行时动态调整向量长度(VL),以适应不同硬件实现的特性(例如矢量寄存器大小)。
概念
1. 向量寄存器
RVV 定义了一组 向量寄存器(Vector Registers, VRs):
- 寄存器名:
v0至v31,共 32 个。 - 每个寄存器的实际宽度(VLEN,以位为单位)由硬件实现决定。例如,硬件可能支持 128 位、256 位或 512 位寄存器。
- 基本元素宽度(SEW,Standard Element Width):表示每个向量元素的大小,例如
8-bit,16-bit,32-bit,64-bit。 - 每个寄存器可以存储的最大元素个数为
VLEN / SEW,称为 最大向量长度(VLmax)。
补充:一个向量元素的最大位宽为ELEN(<VLEN)
本文的位宽都是2的次幂
2.LMUL(Vector register group multiplier)
当一个向量寄存器不够用,就将多个寄存器组进行合并叫做LMUL((合并寄存器组数量),有合并就有拆解,可以分份:1/2,1/4,1/8 (小数表示一个向量寄存器的被使用的位宽)
$$
LMUL >= \frac{SEW}{ELEN}
$$
向量长度(VL)
- 动态向量长度(VL) 是指当前有效的向量长度(单位:元素个数),由程序通过指令动态设置。
- 动态设置使得程序可以在剩余数据不足时调整向量长度,从而避免浪费计算资源。
设置向量长度
1 | size_t vl = __riscv_vsetvl_e32m8(n); |
例如这个函数:获取32位数据(SEW),并且8倍寄存器宽度倍数(LMUL)的数据长度,如果硬件支持的矢量寄存器长度位VLEN是128位,那么根据公式
$$
元素数目 = ( \frac{\text{VLEN}}{\text{SEW}} \times \text{LMUL} = \frac{128}{32} \times 8 = 32 )
$$
因此这个函数是说明一次性处理32个32位数据。
1 | size_t vl = __riscv_vsetvl_e16m1(n); |
还假设VLEN = 128,这个函数将设置一次性处理8个16位数据。
如何计算最终的 VL
对于每次向量指令的实际运行,向量长度(VL)取决于待处理数据的个数 n 和硬件寄存器的处理能力 VLmax(即硬件最大能处理的数据量)。通常 VL 取以下值:
$$
VL = \min(n, \frac{VLEN}{SEW} \times LMUL)
$$
即从待处理元素数 n 和硬件支持的最大向量长度 VLmax 中选择较小的那个值。
- vsetvl_e32m8:假设有 100 个 32 位数据,硬件支持最大处理 32 个 32 位数据,那么: VL=min(100,32)=32VL = \min(100, 32) = 32VL=min(100,32)=32
- vsetvl_e16m1:假设有 10 个 16 位数据,硬件支持最大处理 8 个 16 位数据,那么: VL=min(10,8)=8VL = \min(10, 8) = 8VL=min(10,8)=8
这种动态调整向量长度的方式使得 RVV 架构能够灵活适应不同大小的数据处理,优化性能。
通用Intrinsic编程(手动向量化)
- 使用适当的向量长度设置函数
- 采用合适数据加载存储函数
- 通过向量操作(乘法、加法等)实习复杂运算
- 逐步迭代处理数据
IntrinsicAPI函数解析
Intrinsic 命名遵循着以下通用规则:
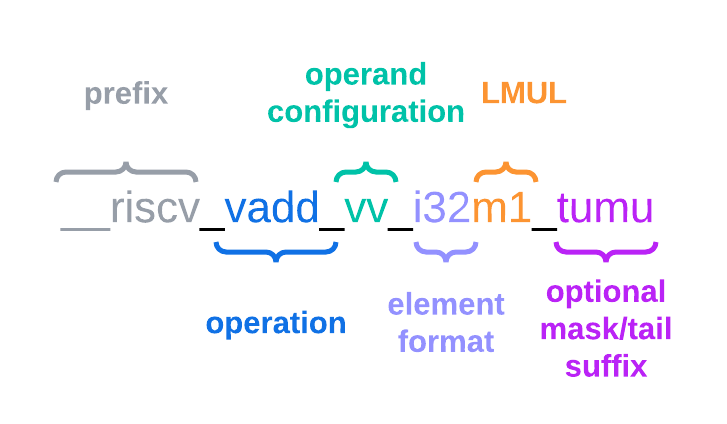
例如:
1 | __riscv_vle8_v_i8mf4 |
构成为:__riscv_前缀,在最新的版本中这个前缀不能省略。
执行操作常用的有:vadd加法,vmul乘法,vle向量加载,vse向量存储,vsetvl设置向量长度。
数据类型:
u32:无符号32整形
f64: 64位浮点型
操作对象是向量还是标量,通过后缀区分,以下为常用操作:
vv:两个向量操作vx:向量与标量操作vi:向量与立即数操作v:针对向量的
LMUL表示向量寄存器逻辑长度是基础寄存器长度的倍数,即VLEN的倍数,例如:
LMUL = 1: 一个逻辑向量寄存器等于一个物理向量寄存器。
LMUL = 2: 一个逻辑向量寄存器需要两个物理向量寄存器。
LMUL = 1/2 或 1/4: 一个物理向量寄存器被划分为多个逻辑寄存器
_tumu是操作掩码
在执行时会参考一个布尔掩码向量(类型通常是 vboolN_t)。掩码决定了哪些向量元素参与计算:
- 掩码值为 1(
true):参与计算。 - 掩码值为 0(
false):跳过计算,通常保留原值或设置为零,具体行为由指令定义。
eg:
1 | vint32m1_t __riscv_vadd_vv_i32m1_m(vbool32_t mask, vint32m1_t dest, vint32m1_t op1, vint32m1_t op2); |
参数解析:
- mask: 掩码向量,类型为
vbool32_t,控制哪些元素参与运算。 - dest: 原目标向量,对于未参与计算的元素,将保留此向量中的对应值。
- op1, op2: 输入向量,表示两个操作数。
输入:
op1 = {1, 2, 3, 4, 5, 6, 7, 8}op2 = {8, 7, 6, 5, 4, 3, 2, 1}mask = {1, 0, 1, 1, 0, 0, 1, 0}
结果:
- 按掩码启用元素计算:
{(1+8), 0, (3+6), (4+5), 0, 0, (7+2), 0} - 最终结果:
{9, 0, 9, 9, 0, 0, 9, 0}
eg:
1 |
|
在实际应用中,选择 SEW 时需要综合考虑以下因素:
- 数据类型(决定了基本的 SEW)。
- 精度要求(高精度需要 64 位,性能优先则选择 32 位)。
- 硬件资源(寄存器长度和支持的 SEW)。
- 并行性能(更小的 SEW 提高并行性,但可能导致精度不足)。
1 |
|
[^为什么仍需要循环?]: 为什么仍需要循环?向量寄存器长度有限,向量寄存器(例如 RVV 中的 VLEN)有固定的硬件限制。例如,VLEN 是 128、256 或 512 位等。每次操作能处理的元素数量取决于:数据类型的大小 (SEW: Scalar Element Width)。当前配置的 LMUL 倍数。如果数据量 n 超过硬件支持的向量长度,就必须分块处理,循环每次操作一个向量块。数据长度不一定是向量寄存器的倍数 数据长度 n 通常不是向量寄存器所能处理的元素数(VLEN / SEW)的整数倍,因此需要动态调整向量长度 (VL) 并处理剩余的尾部数据。循环有助于动态优化 向量化可以动态调整每次处理的元素数,利用循环灵活适配各种数据量。
向量化优化影响要素
1. 数据对齐 (Data Alignment)
向量指令通常要求数据在内存中是对齐的(aligned),以便更高效地加载和存储:
- 对齐数据(如 64 位数据按 8 字节对齐)可以显著提高加载/存储性能。
- 未对齐数据需要额外处理(例如使用
vle64ff等指令),可能导致性能下降。
优化建议:尽量确保输入数据地址是对齐的,尤其在加载和存储时。
2. 数据大小与边界处理
向量化时,处理的数据大小往往不是向量寄存器长度的整数倍:
- 完整向量操作:在主要循环中可以使用完整的向量寄存器。
- 尾部处理:剩余的元素(小于寄存器宽度)需要额外的标量代码或专用尾处理逻辑。RVV 中可以用
vl动态调整处理的元素数量。
优化建议:
- 利用 RVV 的动态向量长度特性,通过调整
vl来处理剩余数据,无需显式的标量处理代码。
3. 数据依赖 (Data Dependency)
- 如果当前迭代的计算依赖于前一迭代的结果(循环相关性),会限制向量化的潜力。
- RVV 提供的掩码操作(masking)可以处理部分依赖问题,但性能可能下降。
优化建议:尝试重写算法,减少循环相关性或数据依赖。
4. 向量化指令集的特性
- RVV 的灵活性:RVV 支持可变长度向量和 SEW,这使得编程灵活性更高,但需要仔细设计循环逻辑以充分利用硬件。
- 向量扩展指令(例如
vfwcvt):将低精度数据扩展为高精度时会引入额外开销。 - 掩码(Mask)操作:对部分元素操作时使用掩码,但这会降低性能,因为部分元素的计算会被跳过。
5. 分支与条件判断
在向量化代码中,分支和条件判断可能导致性能下降:
- RVV 中可以通过掩码指令(masking)处理条件分支,但仍会产生一些冗余操作。
- 如果分支逻辑复杂且数据不均匀,可能需要拆分数据进行分别处理。
优化建议:
- 尽量减少分支逻辑,或将分支替换为掩码操作。
- 优化数据布局,使条件判断逻辑更简单。
6. 向量长度和 LMUL 配置
RVV 的向量寄存器长度(VLEN)和宽度配置(LMUL)会影响并行性能:
- LMUL 增大(如
m4、m8):更多寄存器组合,处理更多数据,性能更高,但资源消耗增加。 - LMUL 减小(如
mf2、mf4):每次操作处理的元素少,功耗低,但并行度下降。
- LMUL 增大(如
优化建议:选择合适的 LMUL,在寄存器使用率和并行度之间找到平衡。
7. 循环展开 (Loop Unrolling)
- 手动展开循环可以减少循环开销(如分支和索引计算),提高性能。
- 但循环展开会增加代码复杂度,可能需要调整以适应不同
VLEN。
优化建议:根据具体硬件配置展开循环,以充分利用寄存器。
